
# 04_diffing 算法
📢 大家好,我是Milo
📢 这篇文章是学习 React 中 diffing算法的学习笔记
# 前言
diff 算法是 React 提升渲染性能的一种优化算法,在 React 中有着很重要的地位,也不止于 React ,在 Vue 中也有 diff 算法,似乎没有差别。在最近的 React 学习中,学到了 diff 算法,感觉视频中的内容有点浅,对 diff 算法不够深入,因此想要深入的了解以下 diff 算法。于是小丞大佬就在掘金,知乎,CSDN 等平台上,看了大量的博客,都非常地不错,可惜看不明白,wwww。所以这篇文章是小丞大佬对于 diff 算法的梳理。
# 什么是虚拟 DOM ?
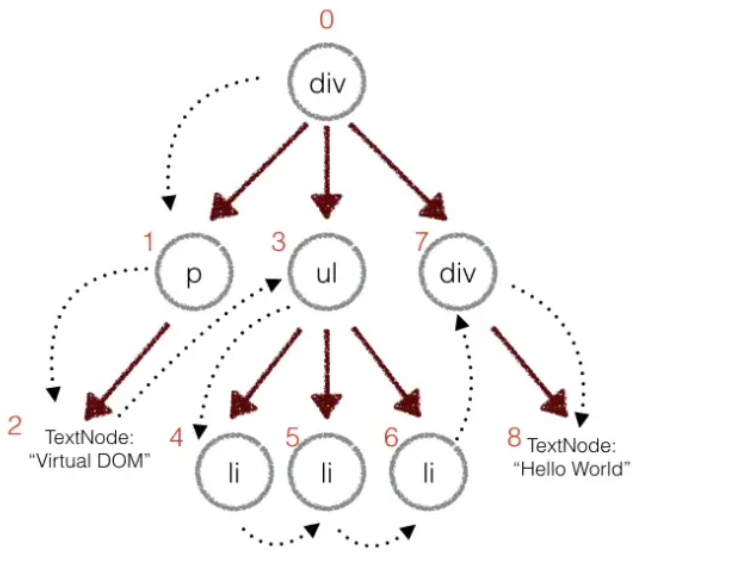
在谈 diff 算法之前,我们需要先了解虚拟 DOM 。它是一种编程概念,在这个概念里,以一种虚拟的表现形式被保存在内存中。在 React 中,render 执行的结果得到的并不是真正的 DOM 节点,而是 JavaScript 对象
虚拟 DOM 只保留了真实 DOM 节点的一些基本属性,和节点之间的层次关系,它相当于建立在 JavaScript 和 DOM 之间的一层“缓存”
<div class="hello">
<span>hello world!</span>
</div>
2
3
上面的这段代码会转化可以转化为虚拟 DOM 结构
{
tag: "div",
props: {
class: "hello"
},
children: [{
tag: "span",
props: {},
children: ["hello world!"]
}]
}
2
3
4
5
6
7
8
9
10
11
其中对于一个节点必备的三个属性 tag,props,children
- tag 指定元素的标签类型,如“
li,div” - props 指定元素身上的属性,如
class,style,自定义属性 - children 指定元素是否有子节点,参数以数组形式传入
而我们在 render 中编写的 JSX 代码就是一种虚拟 DOM 结构。
# 什么是 diff 算法?
其实刚开始学习 React 的时候,很多人可能都听说过 React 很高效,性能很好这类的话语,这其实就是得益于 diff 算法和 Virturl DOM 的完美结合。
单纯的我刚开始会认为
React 也只不过是引入了别人的 diff 算法而已,能有多厉害,又不是原创 ?
但当我查阅了众多资料后,发现被提及最多的是一个 “传统 diff 算法”
其实 React 针对 diff 算法做出的优化,才是我们应当学习的
React 将原先时间复杂度为 O($n^3$) 的传统算法,优化到了 O(n)
大致执行过程图
那 React 是如何实现的呢?
# 三个策略
为了将复杂度降到 O(n),React 基于这三个策略进行了算法优化
- Web UI 中 DOM 节点跨层级的移动操作特别少,可以忽略不计。
- 拥有相同类的两个组件将会生成相似的树形结构,拥有不同类的两个组件将会生成不同的树形结构。
- 对于同一层级的一组子节点,它们可以通过唯一 id 进行区分。
针对这三个策略,React 分别对 tree diff、component diff 以及 element diff 进行算法优化
# tree diff 分层求异
首先会将新旧两个 DOM 树,进行比较,这个比较指的是分层比较。又由于 DOM 节点跨层级的移动操作很少,忽略不计。React 通过 updataDepth 对 虚拟 DOM 树进行层级控制,只会对同层节点进行比较,也就是图中只会对相同颜色方框内的 DOM 节点进行比较。例如:
当对比发现节点消失时,则该节点及其子节点都会被完全删除,不会进行更深层次的比较,这样只需要对树进行一次遍历,便能完成整颗 DOM 树的比较
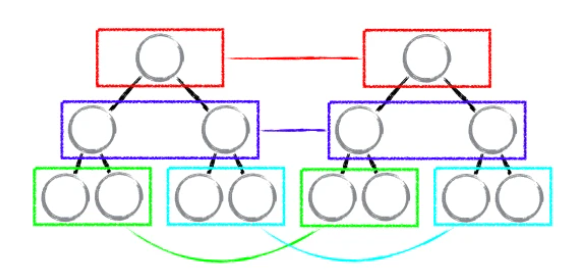
这里还有一个值得关注的地方:DOM 节点跨层级移动
为什么会提出这样的问题呢,在上面的删除原则中,我们发现当节点不存在了就会删除,那我只是给它换位了,它也会删除整个节点及其子节点吗?
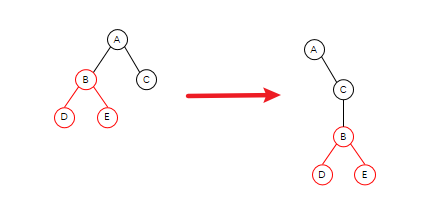
如图,我们需要实现这样的移动,你可能会以为它会直接这样移动
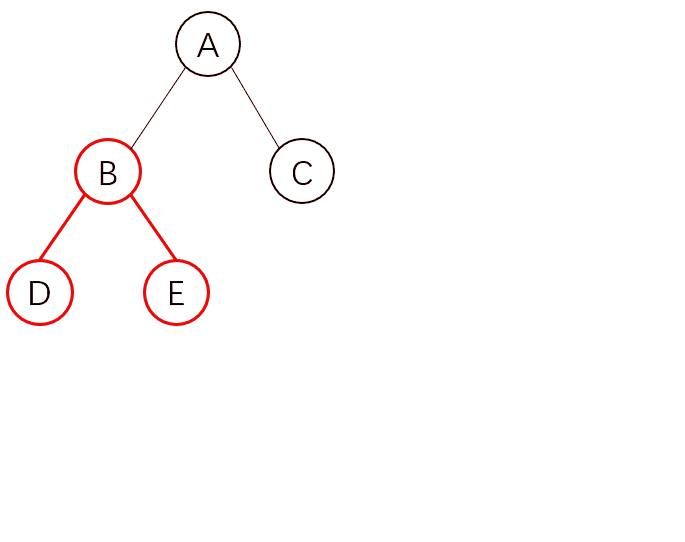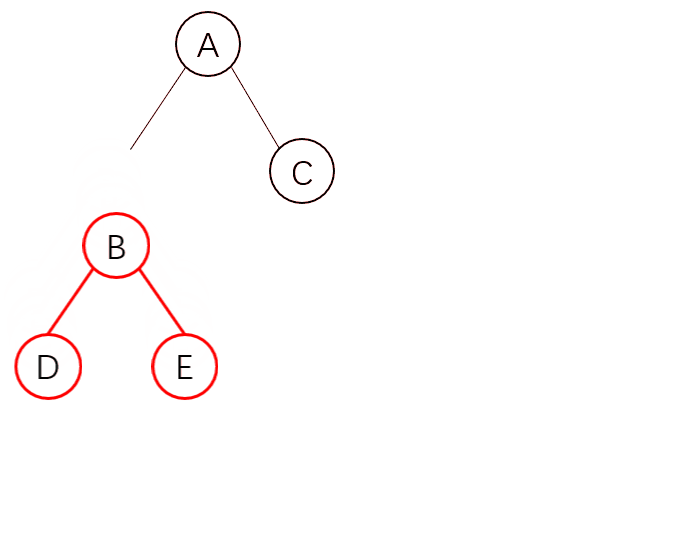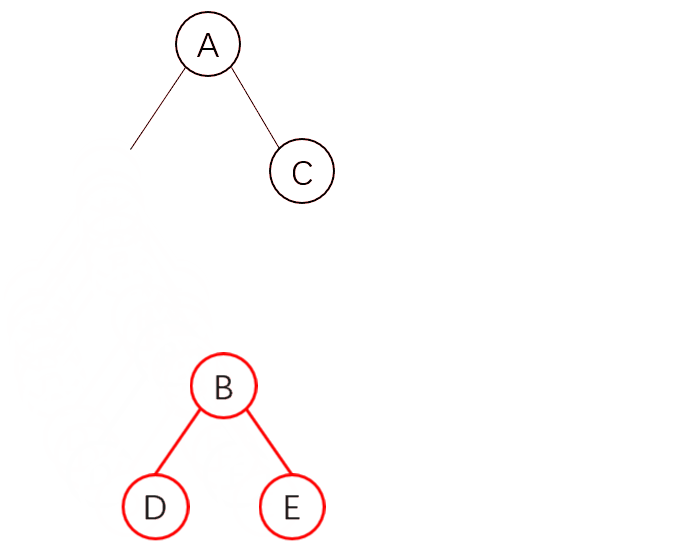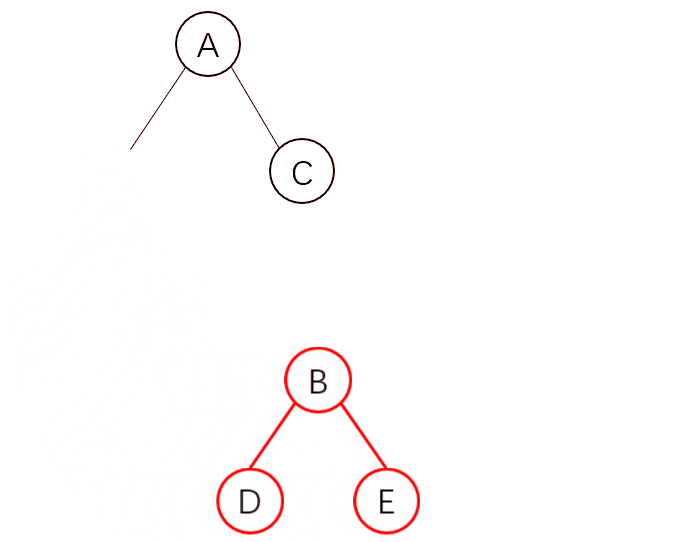
但是实际情况,并不是这样的。由于 React 只会简单的进行同层级节点位置变化,对于不同层级的节点,只有创建和删除操作,当发现 B 节点消失时,就会销毁 B,当发现 C 节点上多了 B 节点,就会创建 B 以及它的子节点。
因此这样会非常的复杂,所以 React 官方并不建议我们进行 DOM 节点跨级操作
# component diff
在组件层面上,也进行了优化
- 如果是同一类型的组件,则按照原策略继续比较 虚拟 DOM tree
- 如果不是,则将这个组件记为
dirty component,从而替换整个组件下的所有子节点
同时对于同一类型的组件,有可能其 Virtual DOM 没有任何变化,如果能够确切的知道这点就可以节省大量的 diff 运算的时间,因此 React 允许用户通过 shouldComponentUpdate() 判断该组件是否需要进行 diff 算法分析
总的来说,如果两个组件结构相似,但被认定为了不同类型的组件,则不会比较二者的结构,而是直接删除
# element diff
element diff 是专门针对同一层级的所有节点的策略。当节点在同一层级时,diff 提供了 3个节点操作方法:插入,移动,删除
当我们要完成如图所示操作转化时,会有很大的困难,因为在新老节点比较的过程中,发现每个节点都要删除再重新创建,但是这只是重新排序了而已,对性能极大的不友好。因此 React 中提出了优化策略:
允许添加唯一值 key 来区分节点
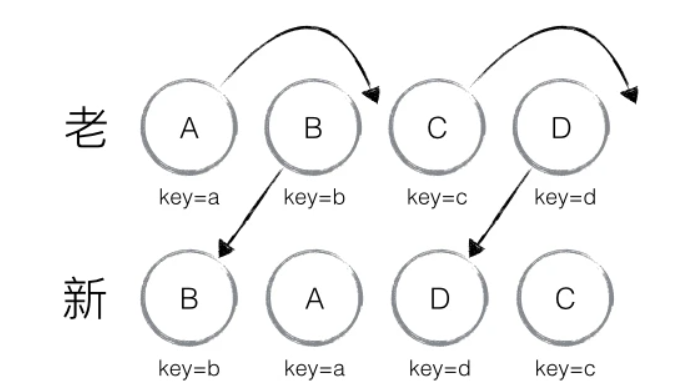
引入 key 的优化策略,让性能上有了翻天覆地的变化
那 key 有什么作用呢?
当同一层级的节点添加了 key 属性后,当位置发生变化时。react diff 进行新旧节点比较,如果发现有相同的 key 就会进行移动操作,而不会删除再创建
那 key 具体是如何起作用的呢?
首先在 React 中只允许节点右移
因此对于上图中的转化,只会进行 A,C 的移动
则只需要对移动的节点进行更新渲染,不移动的则不需要更新渲染
为什么不能用 index 作为 key 值呢?
index 作为 key ,如果我们删除了一个节点,那么数组的后一项可能会前移,这个时候移动的节点和删除的节点就是相同的 key ,在react中,如果 key 相同,就会视为相同的组件,但这两个组件是不同的,这样就会出现很麻烦的事情,例如:序号和文本不对应等问题
所以一定要保证 key 的唯一性
# 建议
React 已经帮我们做了很多了,剩下的需要我们多加注意,才能有更好的性能
基于三个策略我们需要注意
tree diff 建议:开发组件时,需要注意保持 DOM 结构稳定
component diff 建议:使用 shouldComponentUpdate() 来减少不要的更新
element diff 建议:减少最后一个节点移动到头部的操作,这样前面的节点都需要移动
# 经典面试题
1)React中的key有什么作用?(key的内部原理是什么?)
2)为什么遍历列表时,key最好不要用index?
# 1.虚拟DOM中key的作用:
- 简单的说: key是虚拟DOM对象的标识, 在更新显示时key起着极其重要的作用。
详细的说: 当状态中的数据发生变化时,react会根据【新数据】生成【新的虚拟DOM】, 随后React进行【新虚拟DOM】与【旧虚拟DOM】的diff比较,比较规则如下:
a. 旧虚拟DOM中找到了与新虚拟DOM相同的key: (1).若虚拟DOM中内容没变, 直接使用之前的真实DOM (2).若虚拟DOM中内容变了, 则生成新的真实DOM,随后替换掉页面中之前的真实DOM
b. 旧虚拟DOM中未找到与新虚拟DOM相同的key,根据数据创建新的真实DOM,随后渲染到到页面。
# 2.用index作为key可能会引发的问题:
若对数据进行:逆序添加、逆序删除等破坏顺序操作: 会产生没有必要的真实DOM更新 ==> 界面效果没问题, 但效率低。
如果结构中还包含输入类的DOM: 会产生错误DOM更新 ==> 界面有问题。
注意!如果不存在对数据的逆序添加、逆序删除等破坏顺序操作, 仅用于渲染列表用于展示,使用index作为key是没有问题的。
开发中如何选择key?:
- 最好使用每条数据的唯一标识作为key, 比如id、手机号、身份证号、学号等唯一值。
- 如果确定只是简单的展示数据,用index也是可以的。
# 参考资料
谈谈React中Diff算法的策略及实现 (opens new window)
React diff算法 (opens new window)
浅谈react 虚拟dom,diff算法与key机制 (opens new window)
关于手写实现 diff 算法,还有点难度,这事等学完 React 后再说吧
← 03_组件的生命周期 05_初始化脚手架 →